Build Your First QA System

![]()
Question Answering can be used in a variety of use cases. A very common one: Using it to navigate through complex knowledge bases or long documents ("search setting").
A "knowledge base" could for example be your website, an internal wiki or a collection of financial reports. In this tutorial we will work on a slightly different domain: "Game of Thrones".
Let's see how we can use a bunch of Wikipedia articles to answer a variety of questions about the marvellous seven kingdoms.
Prepare environment
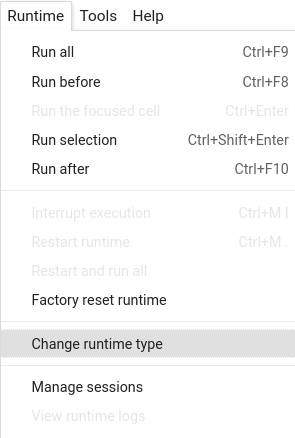
Colab: Enable the GPU runtime
Make sure you enable the GPU runtime to experience decent speed in this tutorial. Runtime -> Change Runtime type -> Hardware accelerator -> GPU
# Make sure you have a GPU running
!nvidia-smi
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack
!pip install --upgrade pip
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers
from haystack.nodes import FARMReader, TransformersReader
Document Store
Haystack finds answers to queries within the documents stored in a DocumentStore. The current implementations of DocumentStore include ElasticsearchDocumentStore, FAISSDocumentStore, SQLDocumentStore, and InMemoryDocumentStore.
Here: We recommended Elasticsearch as it comes preloaded with features like full-text queries, BM25 retrieval, and vector storage for text embeddings.
Alternatives: If you are unable to setup an Elasticsearch instance, then follow the Tutorial 3 for using SQL/InMemory document stores.
Hint: This tutorial creates a new document store instance with Wikipedia articles on Game of Thrones. However, you can configure Haystack to work with your existing document stores.
Start an Elasticsearch server
You can start Elasticsearch on your local machine instance using Docker. If Docker is not readily available in your environment (e.g. in Colab notebooks), then you can manually download and execute Elasticsearch from source.
# Recommended: Start Elasticsearch using Docker via the Haystack utility function
from haystack.utils import launch_es
launch_es()
# In Colab / No Docker environments: Start Elasticsearch from source
! wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
! tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
! chown -R daemon:daemon elasticsearch-7.9.2
import os
from subprocess import Popen, PIPE, STDOUT
es_server = Popen(
["elasticsearch-7.9.2/bin/elasticsearch"], stdout=PIPE, stderr=STDOUT, preexec_fn=lambda: os.setuid(1) # as daemon
)
# wait until ES has started
! sleep 30
# Connect to Elasticsearch
from haystack.document_stores import ElasticsearchDocumentStore
document_store = ElasticsearchDocumentStore(host="localhost", username="", password="", index="document")
Preprocessing of documents
Haystack provides a customizable pipeline for:
- converting files into texts
- cleaning texts
- splitting texts
- writing them to a Document Store
In this tutorial, we download Wikipedia articles about Game of Thrones, apply a basic cleaning function, and index them in Elasticsearch.
# Let's first fetch some documents that we want to query
# Here: 517 Wikipedia articles for Game of Thrones
doc_dir = "data/tutorial1"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt1.zip"
fetch_archive_from_http(url=s3_url, output_dir=doc_dir)
# Convert files to dicts
# You can optionally supply a cleaning function that is applied to each doc (e.g. to remove footers)
# It must take a str as input, and return a str.
docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)
# We now have a list of dictionaries that we can write to our document store.
# If your texts come from a different source (e.g. a DB), you can of course skip convert_files_to_dicts() and create the dictionaries yourself.
# The default format here is:
# {
# 'content': "<DOCUMENT_TEXT_HERE>",
# 'meta': {'name': "<DOCUMENT_NAME_HERE>", ...}
# }
# (Optionally: you can also add more key-value-pairs here, that will be indexed as fields in Elasticsearch and
# can be accessed later for filtering or shown in the responses of the Pipeline)
# Let's have a look at the first 3 entries:
print(docs[:3])
# Now, let's write the dicts containing documents to our DB.
document_store.write_documents(docs)
Initalize Retriever, Reader, & Pipeline
Retriever
Retrievers help narrowing down the scope for the Reader to smaller units of text where a given question could be answered. They use some simple but fast algorithm.
Here: We use Elasticsearch's default BM25 algorithm
Alternatives:
- Customize the
BM25Retrieverwith custom queries (e.g. boosting) and filters - Use
TfidfRetrieverin combination with a SQL or InMemory Document store for simple prototyping and debugging - Use
EmbeddingRetrieverto find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT) - Use
DensePassageRetrieverto use different embedding models for passage and query (see Tutorial 6)
from haystack.nodes import BM25Retriever
retriever = BM25Retriever(document_store=document_store)
# Alternative: An in-memory TfidfRetriever based on Pandas dataframes for building quick-prototypes with SQLite document store.
# from haystack.nodes import TfidfRetriever
# retriever = TfidfRetriever(document_store=document_store)
Reader
A Reader scans the texts returned by retrievers in detail and extracts the k best answers. They are based on powerful, but slower deep learning models.
Haystack currently supports Readers based on the frameworks FARM and Transformers. With both you can either load a local model or one from Hugging Face's model hub (https://huggingface.co/models).
Here: a medium sized RoBERTa QA model using a Reader based on FARM (https://huggingface.co/deepset/roberta-base-squad2)
Alternatives (Reader): TransformersReader (leveraging the pipeline of the Transformers package)
Alternatives (Models): e.g. "distilbert-base-uncased-distilled-squad" (fast) or "deepset/bert-large-uncased-whole-word-masking-squad2" (good accuracy)
Hint: You can adjust the model to return "no answer possible" with the no_ans_boost. Higher values mean the model prefers "no answer possible"
FARMReader
# Load a local model or any of the QA models on
# Hugging Face's model hub (https://huggingface.co/models)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2", use_gpu=True)
TransformersReader
# Alternative:
# reader = TransformersReader(model_name_or_path="distilbert-base-uncased-distilled-squad", tokenizer="distilbert-base-uncased", use_gpu=-1)
Pipeline
With a Haystack Pipeline you can stick together your building blocks to a search pipeline.
Under the hood, Pipelines are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.
To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the ExtractiveQAPipeline that combines a retriever and a reader to answer our questions.
You can learn more about Pipelines in the docs.
from haystack.pipelines import ExtractiveQAPipeline
pipe = ExtractiveQAPipeline(reader, retriever)
Voilà! Ask a question!
# You can configure how many candidates the reader and retriever shall return
# The higher top_k_retriever, the better (but also the slower) your answers.
prediction = pipe.run(
query="Who is the father of Arya Stark?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 5}}
)
# prediction = pipe.run(query="Who created the Dothraki vocabulary?", params={"Reader": {"top_k": 5}})
# prediction = pipe.run(query="Who is the sister of Sansa?", params={"Reader": {"top_k": 5}})
# Now you can either print the object directly...
from pprint import pprint
pprint(prediction)
# Sample output:
# {
# 'answers': [ <Answer: answer='Eddard', type='extractive', score=0.9919578731060028, offsets_in_document=[{'start': 608, 'end': 615}], offsets_in_context=[{'start': 72, 'end': 79}], document_id='cc75f739897ecbf8c14657b13dda890e', meta={'name': '454_Music_of_Game_of_Thrones.txt'}}, context='...' >,
# <Answer: answer='Ned', type='extractive', score=0.9767240881919861, offsets_in_document=[{'start': 3687, 'end': 3801}], offsets_in_context=[{'start': 18, 'end': 132}], document_id='9acf17ec9083c4022f69eb4a37187080', meta={'name': '454_Music_of_Game_of_Thrones.txt'}}, context='...' >,
# ...
# ]
# 'documents': [ <Document: content_type='text', score=0.8034909798951382, meta={'name': '332_Sansa_Stark.txt'}, embedding=None, id=d1f36ec7170e4c46cde65787fe125dfe', content='\n===\'\'A Game of Thrones\'\'===\nSansa Stark begins the novel by being betrothed to Crown ...'>,
# <Document: content_type='text', score=0.8002150354529785, meta={'name': '191_Gendry.txt'}, embedding=None, id='dd4e070a22896afa81748d6510006d2', 'content='\n===Season 2===\nGendry travels North with Yoren and other Night's Watch recruits, including Arya ...'>,
# ...
# ],
# 'no_ans_gap': 11.688868522644043,
# 'node_id': 'Reader',
# 'params': {'Reader': {'top_k': 5}, 'Retriever': {'top_k': 5}},
# 'query': 'Who is the father of Arya Stark?',
# 'root_node': 'Query'
# }
# ...or use a util to simplify the output
# Change `minimum` to `medium` or `all` to raise the level of detail
print_answers(prediction, details="minimum")
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Slack | GitHub Discussions | Website
By the way: we're hiring!