Long-Form Question Answering
![]()
Prepare environment
Colab: Enable the GPU runtime
Make sure you enable the GPU runtime to experience decent speed in this tutorial.
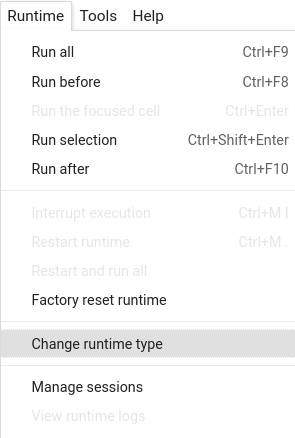
Runtime -> Change Runtime type -> Hardware accelerator -> GPU
# Make sure you have a GPU running
!nvidia-smi
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack
!pip install --upgrade pip
!pip install -q git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]
from haystack.utils import convert_files_to_docs, fetch_archive_from_http, clean_wiki_text
from haystack.nodes import Seq2SeqGenerator
Document Store
FAISS is a library for efficient similarity search on a cluster of dense vectors.
The FAISSDocumentStore uses a SQL(SQLite in-memory be default) database under-the-hood
to store the document text and other meta data. The vector embeddings of the text are
indexed on a FAISS Index that later is queried for searching answers.
The default flavour of FAISSDocumentStore is "Flat" but can also be set to "HNSW" for
faster search at the expense of some accuracy. Just set the faiss_index_factor_str argument in the constructor.
For more info on which suits your use case: https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
from haystack.document_stores import FAISSDocumentStore
document_store = FAISSDocumentStore(embedding_dim=128, faiss_index_factory_str="Flat")
Cleaning & indexing documents
Similarly to the previous tutorials, we download, convert and index some Game of Thrones articles to our DocumentStore
# Let's first get some files that we want to use
doc_dir = "data/tutorial12"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt12.zip"
fetch_archive_from_http(url=s3_url, output_dir=doc_dir)
# Convert files to dicts
docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)
# Now, let's write the dicts containing documents to our DB.
document_store.write_documents(docs)
Initalize Retriever and Reader/Generator
Retriever
We use a DensePassageRetriever and we invoke update_embeddings to index the embeddings of documents in the FAISSDocumentStore
from haystack.nodes import DensePassageRetriever
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model="vblagoje/dpr-question_encoder-single-lfqa-wiki",
passage_embedding_model="vblagoje/dpr-ctx_encoder-single-lfqa-wiki",
)
document_store.update_embeddings(retriever)
Before we blindly use the DensePassageRetriever let's empirically test it to make sure a simple search indeed finds the relevant documents.
from haystack.utils import print_documents
from haystack.pipelines import DocumentSearchPipeline
p_retrieval = DocumentSearchPipeline(retriever)
res = p_retrieval.run(query="Tell me something about Arya Stark?", params={"Retriever": {"top_k": 10}})
print_documents(res, max_text_len=512)
Reader/Generator
Similar to previous Tutorials we now initalize our reader/generator.
Here we use a Seq2SeqGenerator with the vblagoje/bart_lfqa model (see: https://huggingface.co/vblagoje/bart_lfqa)
generator = Seq2SeqGenerator(model_name_or_path="vblagoje/bart_lfqa")
Pipeline
With a Haystack Pipeline you can stick together your building blocks to a search pipeline.
Under the hood, Pipelines are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.
To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the GenerativeQAPipeline that combines a retriever and a reader/generator to answer our questions.
You can learn more about Pipelines in the docs.
from haystack.pipelines import GenerativeQAPipeline
pipe = GenerativeQAPipeline(generator, retriever)
Voilà! Ask a question!
pipe.run(
query="How did Arya Stark's character get portrayed in a television adaptation?", params={"Retriever": {"top_k": 3}}
)
pipe.run(query="Why is Arya Stark an unusual character?", params={"Retriever": {"top_k": 3}})
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source! Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Slack | GitHub Discussions | Website
By the way: we're hiring!